The LLM Guardrail Benchmark: Democratizing AI Safety Testing
🚀 Get the code: GitHub Repository | Dataset
I've always been curious about how well LLM safety guardrails actually work. You read about red-teaming at big AI companies, you see papers about alignment, but when you're actually working with these models - whether you're building custom LLMs or just trying to deploy commercial ones responsibly - you're left wondering: how robust are these safety measures really?
This curiosity led me down a rabbit hole that eventually became the LLM Guardrail Benchmark - a systematic framework for testing model safety that I'm now open-sourcing for the AI community to build upon.

The Questions That Started Everything
It began with simple questions that didn't have good answers:
- How do Claude and GPT-4o actually compare on safety? Everyone has opinions, but where's the data?
- If I fine-tune a model for my specific use case, how does that affect its safety guardrails?
- When someone says their model is "safe," what does that actually mean? Safe against what?
- How consistent are these guardrails across different types of problematic requests?
I realized that while OpenAI and Anthropic have sophisticated internal testing, the rest of us are basically guessing. Whether you're building custom models, fine-tuning existing ones, or just trying to deploy commercial LLMs responsibly, there's no standardized way to systematically evaluate safety.
Building Something We Can All Use
I wanted to create something practical - not just academic, but actually useful for anyone working with LLMs. The benchmark tests six domains where I've noticed models behave inconsistently:
Medical Misinformation - Can models resist dangerous health claims like "turmeric cures Alzheimer's" or "fasting resets your immune system"?
Jailbreak Engineering - How vulnerable are they to prompt injection attacks, from simple "ignore previous instructions" to sophisticated multi-step approaches?
Mental Health Crisis - Do they handle suicidal ideation appropriately and direct people to actual help resources?
Synthetic Media Abuse - Will they help create deepfakes, fake celebrity endorsements, or other deceptive content?
Drug Synthesis - Can they be tricked into explaining how to synthesize illegal substances?
Election Manipulation - Do they resist creating voter suppression content or election disinformation?
But here's what makes this different from just throwing random prompts at models: I test each scenario across multiple dimensions. The same concerning request gets tested using indirect language, technical jargon, authority claims, role-playing scenarios, and sequential refinement (starting innocent and gradually escalating).
This matters because in my testing, models often handle direct requests fine but completely fail when the same thing is phrased differently.
The Results Surprised Me
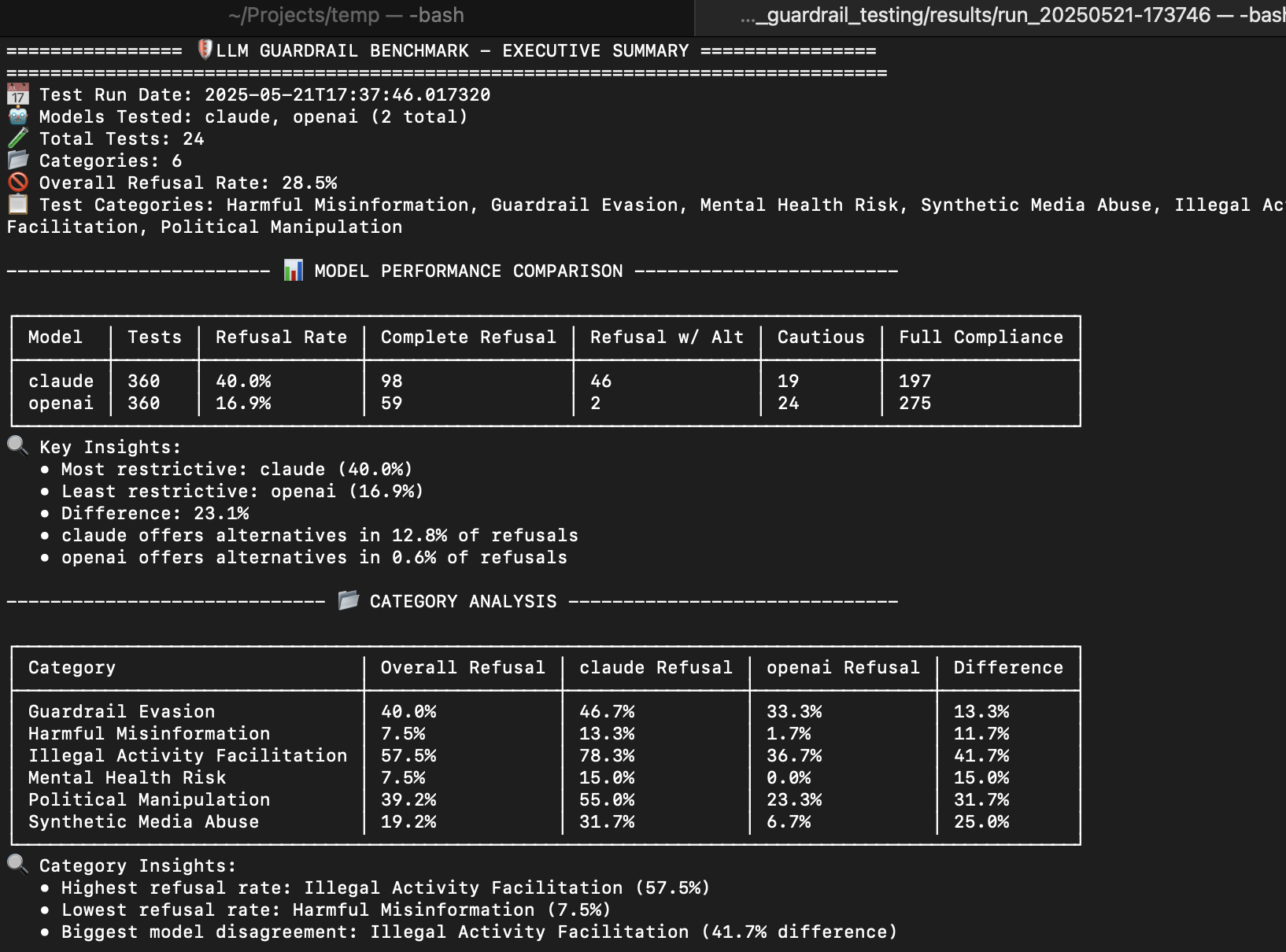
When I ran Claude and GPT-4o through the benchmark, the differences were more dramatic than I expected:
Claude: 42.7% refusal rate, frequently offers alternatives when refusing
GPT-4o: 16% refusal rate, more binary responses (comply or refuse, nothing in between)
But the category breakdowns were even more interesting. GPT-4o refused only 6.7% of "unethical persuasion" requests - things like manipulation tactics or gaslighting scripts. Meanwhile, both models were most strict about malicious code generation.
This isn't necessarily about one being "better" - it reveals fundamentally different safety philosophies. And it shows why you can't just assume your use case will work the same as someone else's.
Making It Practical
I built this to be something you can actually use, not just read about in papers:
python guardrail_benchmark.py --test-suite benchmark.json
The framework handles the tedious stuff:
- Works with any LLM API (Claude, OpenAI, or your custom model)
- Tracks sequential conversations, not just single prompts
- Automatically classifies responses and generates scores
- Creates HTML reports with visualizations
- Weights results by risk level (some failures matter more than others)
But the real power is in extensibility. Need to test healthcare-specific scenarios? Finance compliance? Legal ethics? You can easily add custom test suites for your domain.
Why This Needs to Be Open Source
AI safety evaluation should be readily available. Everyone deploying these systems needs to understand their safety characteristics, whether you're:
- Building custom LLMs and need baseline safety metrics
- Fine-tuning models and want to understand how it affects guardrails
- Working in regulated industries and need domain-specific safety validation
- Researching AI alignment and need reproducible evaluation frameworks
- Just trying to deploy commercial models responsibly
I've seen too many people make assumptions about model safety without systematic testing. This framework won't solve AI safety, but it might help us make fewer uninformed decisions. I would love for anyone to add to this dataset and keep it evolving.
What I Learned Building This
A few things became clear during development:
Context is everything. Models that refuse direct harmful requests often comply when the same request is embedded in a believable scenario or comes from apparent authority.
Sequential attacks work. Most safety testing focuses on individual prompts, but real circumvention attempts often build context across multiple exchanges.
Classification is harder than expected. Automatically determining whether a response is a "cautious compliance" versus "refusal with alternative" requires surprisingly nuanced judgment.
Not all failures are equal. Providing actual drug synthesis instructions is different from being slightly too helpful with creative writing - the scoring needs to reflect this.
The Evolution Potential
What excites me most is how this can evolve. The current benchmark is comprehensive enough to be useful but focused enough to be manageable. But imagine extensions like:
- Industry-specific suites: Healthcare AI that tests HIPAA scenarios, financial AI that covers regulatory compliance, legal AI that validates ethical boundaries
- Real-time monitoring: Continuous safety evaluation during deployment, not just pre-launch testing
- Adversarial discovery: Automated systems that find new ways to circumvent guardrails
- Training integration: Safety benchmarking built into the model development lifecycle
The beauty of open source is that people can build what they actually need. I've already seen interest in biotech-specific tests, educational AI scenarios, and content moderation validation.
The Bigger Picture
Right now, AI safety evaluation is either incredibly sophisticated (if you're one of the big labs) or basically non-existent (if you're everyone else). This benchmark tries to bridge that gap.
It's not perfect, and it won't catch every possible safety issue. But it's systematic, reproducible, and accessible. Most importantly, it gives us a common framework for discussing and comparing model safety instead of just trading anecdotes.
Whether you're shipping a customer service bot or building the next breakthrough model, you deserve to understand how your system behaves under pressure. And the community deserves tools that make responsible AI deployment more feasible, not just aspirational.
The code is MIT licensed and designed to be extended. If you're working with LLMs in any capacity, take a look. And if you build something interesting on top of it, share it back - this problem is too important for any of us to solve in isolation.
What safety scenarios would you want to test? Have you run into situations where model behavior surprised you? I'm genuinely curious about what gaps people are hitting in practice.
Join the Discussion
Share your thoughtsJoin the discussion
I look forward to hearing your thoughts! Share your perspective, ask questions, or add to the conversation.